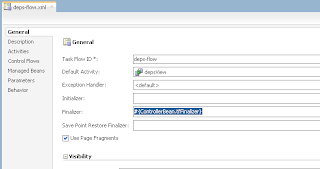
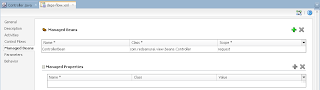
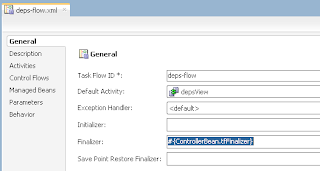
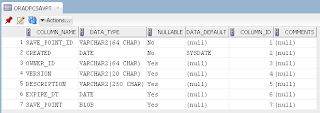
ADF BC API provides method to lock current row, but lock lifetime can be short. Lock method issues SQL lock and locks the record for current user. If your use case is to keep lock for longer period of time, in other words to reserve record by the user until commit or rollback - this is not the method you should use. Lock issued from ADF BC can be released automatically, before user will be committing his changes. This happens when DB pooling is enabled or when there are more concurrent users than AM pool can handle. If you want to make sure that record will be reserved by the user for certain period of time, you must implement custom flag column in the DB and update it separately.
In this post I will demo, why you should avoid using ADF BC lock method to reserve current row by the user. Here you can download sample application - LockApp.zip.
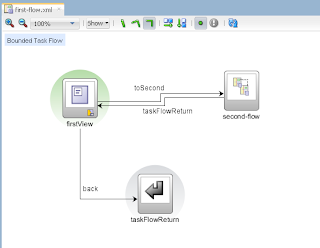
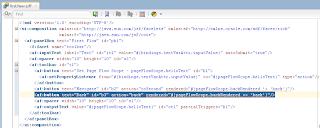
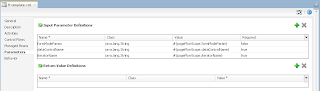
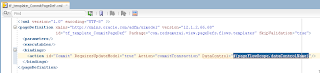
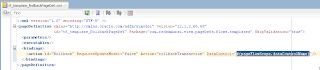
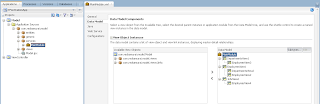
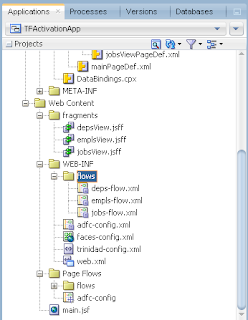
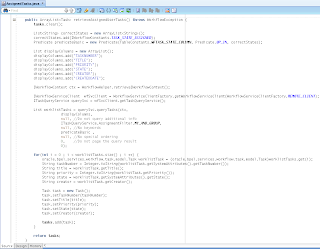
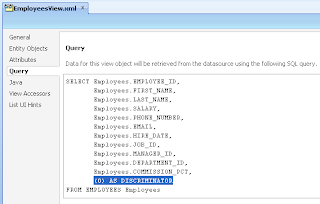
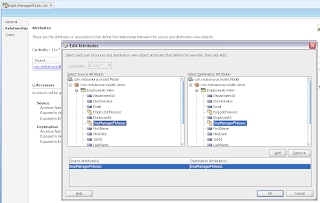
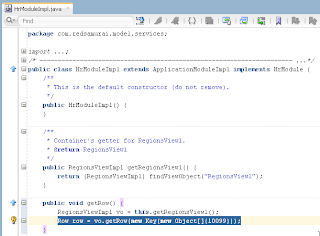
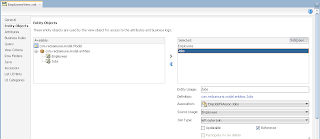
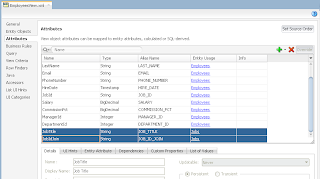
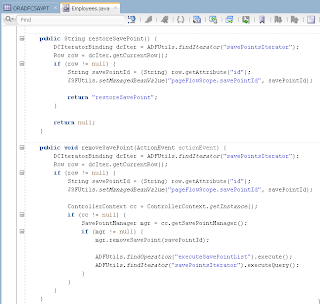
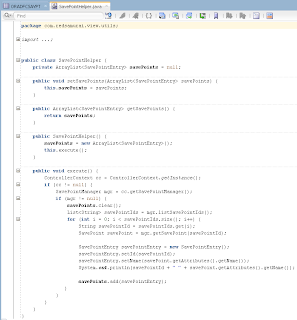
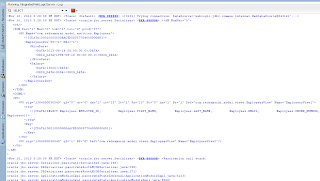
VO implements a custom method exposed to the Data Control, where ADF BC API lock() method is called for current row - this issues SQL lock in the DB for current row:
![]()
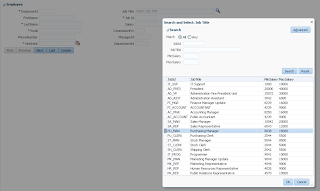
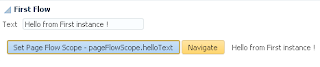
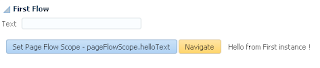
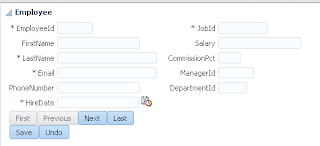
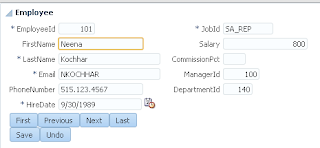
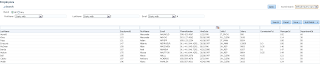
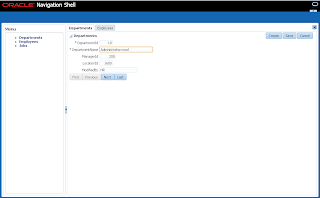
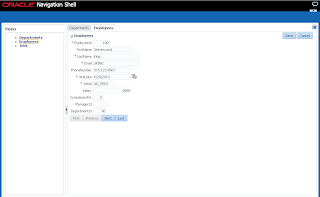
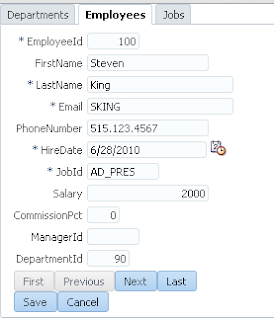
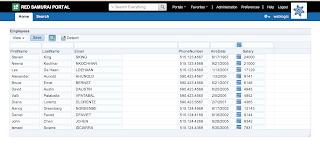
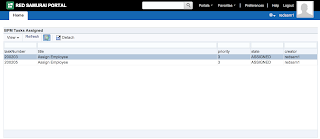
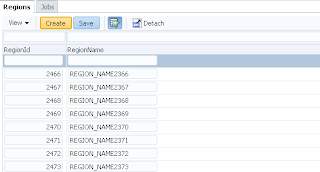
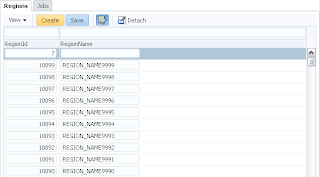
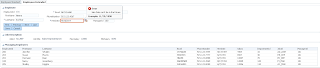
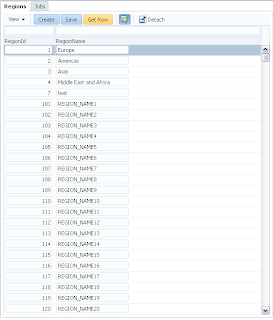
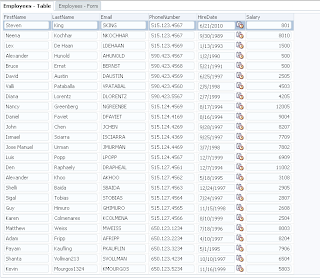
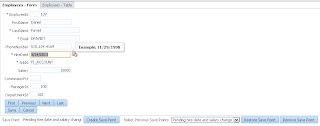
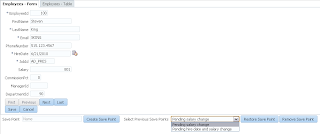
User A opens ADF form, selects record with ID = 102 and invokes our method to lock the record:
![]()
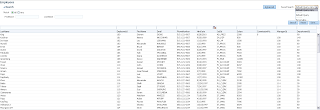
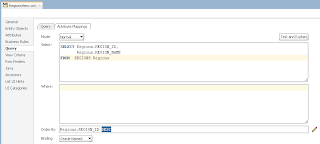
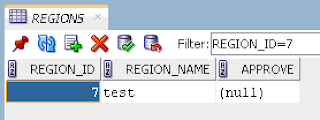
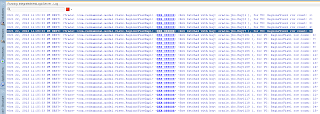
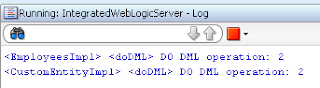
We can see SQL statement executed in the DB - lock is set successfully:
![]()
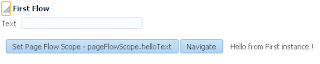
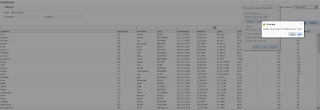
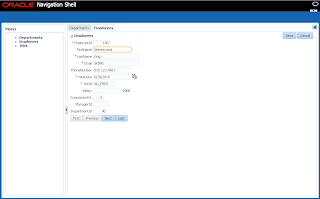
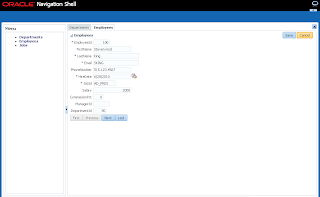
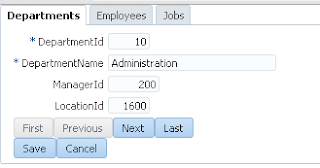
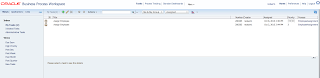
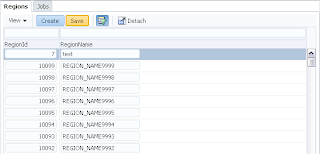
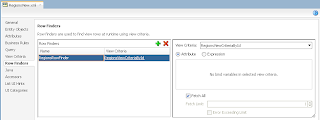
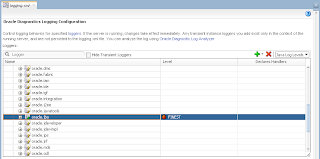
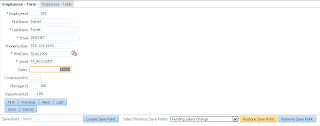
User B opens ADF form, selects record with ID = 102 and invokes lock method - error is generated. Since user A still holds a lock:
![]()
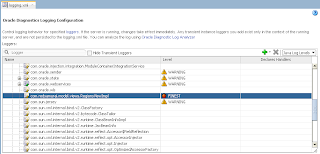
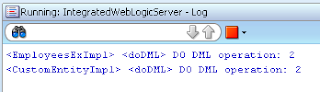
We can see this from SQL log - lock attempt was not successful:
![]()
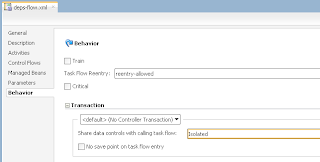
Lock remains for user A only in perfect scenario. In real life, when more users will be accessing your system, at some point AM pooling will start working and AM instances will be switching between users. When AM instance is switched, DB connection is reset and current lock will be lost.
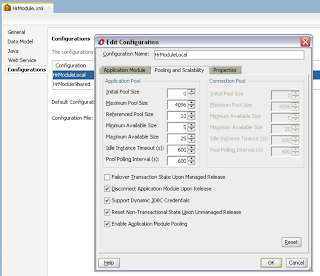
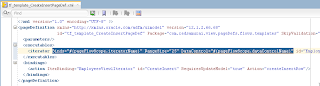
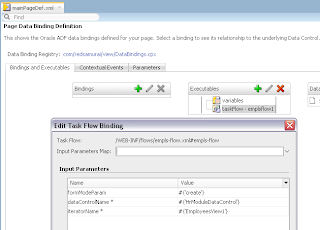
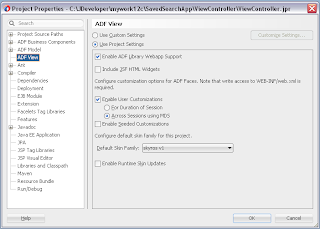
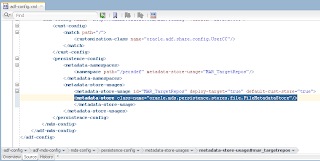
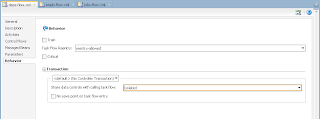
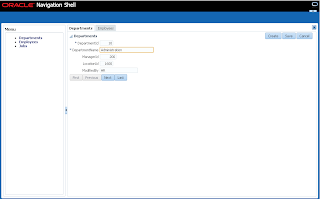
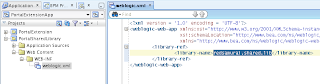
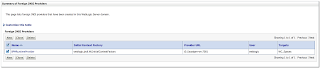
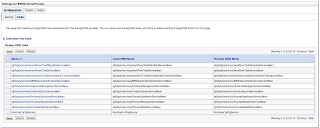
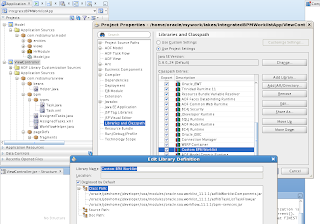
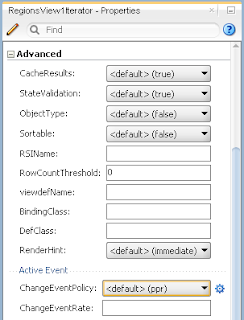
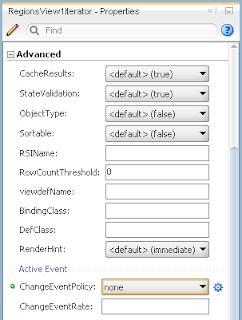
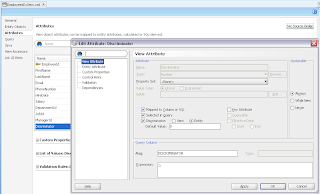
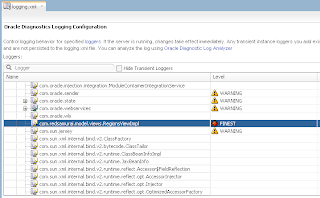
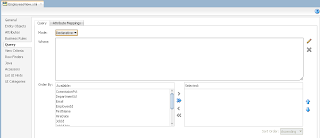
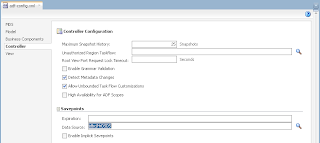
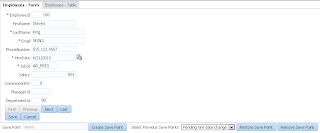
In order to simulate loosing of lock, I set Referenced Pool Size = 1. This means AM will support only 1 user, if there will be more users - AM pooling will be working and AM instance will be shared between users:
![]()
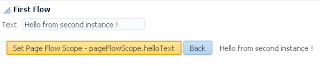
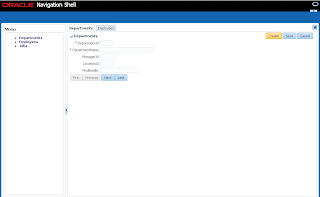
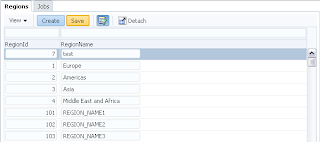
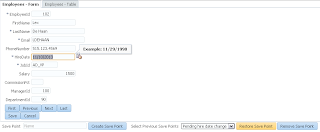
User B can set a lock now, even before user A releases his lock. This means user A will be loosing reserved row before doing a commit/rollback:
![]()
In this post I will demo, why you should avoid using ADF BC lock method to reserve current row by the user. Here you can download sample application - LockApp.zip.
VO implements a custom method exposed to the Data Control, where ADF BC API lock() method is called for current row - this issues SQL lock in the DB for current row:

User A opens ADF form, selects record with ID = 102 and invokes our method to lock the record:

We can see SQL statement executed in the DB - lock is set successfully:

User B opens ADF form, selects record with ID = 102 and invokes lock method - error is generated. Since user A still holds a lock:

We can see this from SQL log - lock attempt was not successful:

Lock remains for user A only in perfect scenario. In real life, when more users will be accessing your system, at some point AM pooling will start working and AM instances will be switching between users. When AM instance is switched, DB connection is reset and current lock will be lost.
In order to simulate loosing of lock, I set Referenced Pool Size = 1. This means AM will support only 1 user, if there will be more users - AM pooling will be working and AM instance will be shared between users:

User B can set a lock now, even before user A releases his lock. This means user A will be loosing reserved row before doing a commit/rollback: